Al igual que en otras ciencias y en la mayoría de las actividades que están vinculadas al desarrollo moderno de nuestra sociedad (por ejemplo, comercio, entretenimiento, industria, seguridad, etcétera) la Astronomía está siendo abarrotada de información por un crecimiento exponencial en el volumen y complejidad de datos observacionales y teóricos que se van generando en todo el mundo (Szalay & Gray 2000). Se estima que la cantidad de información acumulada se duplica cada 18 meses y por lo tanto el crecimiento en volumen cumple perfectamente con la ley de Moore (1965).
Esto no es una casualidad, ya que mientras el avance del área de los espejos primarios de los telescopios a lo largo de los años se ha duplicado aproximadamente cada 25 años, el número de píxeles de un detector CCD (Charged Coupled Device) se duplica cada 2 años (ver figura 1). Esto quiere decir que aun cuando el tamaño de los telescopios permanezca fijo durante cierto tiempo, el tener detectores CCDs más grandes y más sensibles implica generar archivos cada vez de mayor tamaño.
Esto trae como consecuencia un serio desafío a la comunidad científica internacional, ya que la cantidad de información astronómica a la que se enfrenta los grupos de investigación es realmente muy grande. Por ejemplo, hace apenas 7 años ya se calculaban el contenido de bases de datos astronómicas en varios cientos de TB (1 Terabyte = mil Gigabytes = un millón de Megabytes) (Brunner et al. 2002) y a principios de 2005 la tasa de recolección de datos se estimaba aproximadamente a un Terabyte (TB) por día. Entonces, dado que tanto el volumen de datos, así como sus tasas de recolección están creciendo exponencialmente, podríamos pensar que en pocos años nos estaremos enfrentando a bases de datos de varios PB.

operar adecuadamente la información masiva producida por diferentes medios que se utilizan para estudiar el Universo; telescopios y modelos numéricos. Un OV ofrece un ambiente federativo internacional virtual de investigación, basado en nuevas tecnologías de la información e Internet, completamente abierto a científicos y estudiantes que desean trabajar con conjuntos de datos astronómicos reales. Esta herramienta computacional reúne archivos de datos y servicios, así como complejas técnicas de exploración (minería de datos) y análisis de datos. Un OV es un excelente pretexto para realizar proyectos multidisciplinarios dónde colaboren astrofísicos y especialistas en ciencias e ingeniería de la computación (Djorgovski & Williams, 2005). Y por si fuera poco, dicho concepto puede extenderse y aplicarse fácilmente a otras áreas de la ciencia y de la sociedad en general que generan y almacenan datos de manera frecuente, como es el caso del Instituto Nacional de Estadística, Geografía e Informática (INEGI).
La definición de OV fue propuesta en la década de los años 90 a través de un sinnúmero de discusiones y talleres realizados durante el Simposio 179 de la Unión Astronómica Internacional y en la Reunión 192 de la American Astronomical Society (Djorgovski, & Beichman, 1998) En dichas discusiones se acordó que el acceso electrónico, vía Internet, a las bases de datos astronómicos de todo el mundo, es vital para investigar los detalles de nuestro Universo. Una base de datos por si sola es importante, no obstante, si deseamos realizar investigaciones que requieran un estudio multi-espectral, o pancromático, debemos tener acceso a varias bases de datos.
Así pues, los observatorios virtuales tienen como una de sus tareas fundamentales dar acceso a los astrónomos mexicanos y de todo el mundo a la información almacenada en dichas bases de datos, independientemente del lugar geográfico donde se generen o almacenen los datos. Por ejemplo, si queremos entender los detalles de la expansión de Universo y la formación de la galaxias, necesitamos hacer estudios estadísticos de tipos específicos de galaxias, así como de sus distancias y del medio ambiente donde se localizan. Esto requiere de imágenes en diferentes longitudes de onda, de miles o millones de galaxias, así como el conocimiento de sus distancias. Esta tarea resultaría casi imposible de lograr con una sola base de datos.
Arquitectura de los Observatorios Virtuales
Como ya se mencionó, un OV es una herramienta computacional que permite almacenar, accesar y procesar información de manera eficiente en grandes bases de datos distribuidas alrededor de todo el mundo, utilizando intensivamente el Internet para operar sobre los datos. De manera general podemos decir que normalmente están compuestos por varios módulos como los asociados a: la adquisición y la operabilidad de los datos, la generación de las bases de datos, las herramientas de búsquedas en las distintas bases, el diseño y desarrollo de las herramientas de reducción y procesamiento, los relacionados con la visualización, etcétera. El éxito de los OV radica en la capacidad de poder interactuar entre las distintas bases de datos de manera sencilla desde una computadora de escritorio conectada a la red, la Alianza Internacional de Observatorios Virtuales, (IVOA por sus siglas en inglés), es la entidad federativa responsable de dictar los estándares sobre la forma de “operar” los OV. Estos estándares van desde la manera en la que se “etiquetan” los datos (generar el metadato) hasta la implementación de herramientas computacionales que se aplicarán sobre ellos.
Existen diferentes grupos de trabajo en el IVOA que se encargan de generar estos estándares, los cuales están relacionados con las aplicaciones, los sistemas de búsquedas, la forma de comunicar las bases de datos, la modelación de los datos, la generación de reglas para los metadatos, entre otros. IVOA agrupa a 15 países (Alemania, Armenia, Australia, Cánada, China, España, Estados Unidos, Francia, Hungría, India, Italia, Japón, Korea, Reino Unido y Rusia,) y a la Comunidad Europea (ver figura 2), algunos de los miembros cuentan con telescopios terrestres o naves espaciales, como es el caso de Estados Unidos, pero otros no, tal como la India, sin embargo, todos trabajan en el desarrollo de diversas herramientas computacionales para operar las bases de datos, que están disponibles para la comunidad científica.
 Figura 2. Alianza Internacional de Observatorios Virtuales.
Figura 2. Alianza Internacional de Observatorios Virtuales.
Afortunadamente, ya es posible contar con un gran número de herramientas que facilitan la manera de llevar a cabo la minería de datos, la cual consiste literalmente en “extraer” la información valiosa de una “montaña de datos”. Existen aplicaciones desarrolladas por el grupo de programadores del IVOA, como TOPCAT, por mencionar alguna, que mediante una interfase gráfica interactiva proporciona muchas de las facilidades que los astrónomos necesitan para analizar y manipular datos (ver figura 3), por ejemplo, maneja diferentes formatos de datos como FITS y VOTable, además de ofrecer diferentes formas de visualizarlos y analizarlos. Cabe mencionar que una de sus principales fortalezas es la de acceder rápidamente a grandes volúmenes de datos.
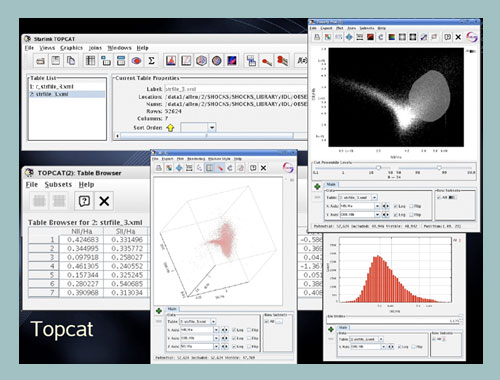
Figura 3. Ejemplo del tipo interfases que utiliza Topcat (Mark Allen).
Observatorios Virtuales Teóricos
Es bien sabido que las simulaciones numéricas juegan un papel fundamental para estudiar y entender la evolución de diferentes eventos astronómicos que ocurren en el Universo, ya que estos fenómenos cósmicos necesitan de miles o millones de años para desarrollarse y nos sería imposible llevar un seguimiento puntual debido a que los seres humanos vivimos en promedio 80 años. Hoy en día gracias al uso de equipos de cómputo de alto rendimiento y al desarrollo de complejos códigos numéricos astrofísicos, es posible llevar a cabo simulaciones numéricas astrofísicas con gran detalle a muy alta resolución. Esto trae como consecuencia que la cantidad de datos generados por cada una de estas simulaciones sea muy grande, no sólo por la simulación numérica resultante, sino porque para llegar al resultado deseado en ocasiones se requiere llevar a cabo un sinnúmero de cálculos numéricos previos.
El concepto de Observatorio Virtual Teórico (OVT), está estrechamente relacionado con un OV, sólo que en lugar de almacenar datos obtenidos con telescopios, esta conformado por datos generados por modelos astrofísicos teóricos. El objetivo de este tipo de observatorios es el de proporcionar a la comunidad científica con poca o nula experiencia en códigos numéricos, una serie de herramientas computacionales que le permitan realizar simulaciones numéricas, ejecutando remotamente un código o bien utilizando datos de cálculos numéricos que ya han sido ejecutados con anterioridad, aprovechando las características que ofrece el envío de datos por Internet y en su caso las redes de alta velocidad.
En el 2004 se creó el “IVOA Theory Interest Group”, el cual tiene como objetivo principal garantizar que los datos teóricos estén considerados en los procesos de estandarización del Observatorio Virtual, una de sus principales tareas es desarrollar herramientas que permitan comparar los resultados teóricos con las observaciones y viceversa. Algunos ejemplos de OVT que se han realizado en otros países se pueden ver en la tabla 1.
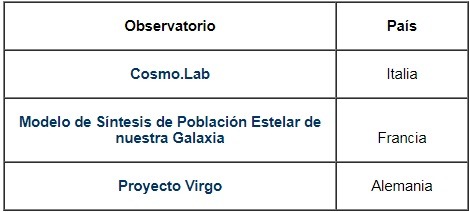
Tabla 1. Ejemplos de algunos Observatorios Virtuales Teóricos.
Observatorio Virtual Solar Mexicano
En el caso particular de México, la UNAM a través de la Dirección General de Servicios de Cómputo Académico y de los Institutos de Astronomía y Ecología desarrollaron el primer Observatorio Virtual Solar de nuestro país, el Observatorio Virtual Solar Mexicano (OVSM). Este fue diseñado a partir de la premisa de crear una herramienta computacional sencilla de utilizar, que cumpliera con los requisitos básicos de un Observatorio Virtual, donde la base de datos se genera automáticamente con resultados de simulaciones numéricas que son ejecutadas remotamente en un servidor, y no con datos observacionales. Sus características hacen que sea una excelente opción para que estudiantes o investigadores que trabajan con datos observacionales, cuenten con un modelo hidrodinámico opcional que les permita interpretar sus datos.
Es importante mencionar que esta herramienta computacional está diseñada para académicos que no cuentan con equipos de cómputo de alto rendimiento o no son expertos en códigos numéricos, todo se hace a través de una interfase web intuitiva. Hasta el momento el OVSM está orientado al estudio de la Evolución de Eyecciones de Masa Coronal (EMC) en el Medio Interplanetario, tema de gran interés para investigadores dedicados a estudiar problemas vinculados al clima espacial, el cual es un conjunto de fenómenos e interacciones que se desarrollan en el medio interplanetario y que está regulado fundamentalmente por la actividad que se origina en el Sol, y nos proporciona información sobre el estado de perturbación del ambiente entre la Tierra y el Sol (ver figura 4).

Figura 4. En esta imagen se muestran 2 EMC simétricamente opuestas. Las observaciones se realizaron el 8.Diciembre.2000 con la nave espacial SOHO, utilizando el coronógrafo LASCO-C2. Una imagen del EIT tomada el mismo día ha sido sobrepuesta en lo que sería el coronógrafo C2, el cual es usado para ocultar la luz fotosférica y poner así de manifiesto la débil señal coronal en luz blanca. (Solar & Heliospheric Observatory, SOHO).
La arquitectura computacional del OVSM está basada en tres módulos; el primero corresponde al diseño de la Interfaz gráfica de usuario (GUI por sus siglas en inglés), el segundo está relacionado con la ejecución de la simulación numérica remota y el tercero con la generación de la base de datos. Cada uno de estos módulos está vinculado entre sí (ver Hernández-Cervantes, et al. 2008).
Algunos ejemplos de otros Observatorios Virtuales Solares que se han desarollado se muestran en la tabla 2.

Tabla 2. Ejemplos de algunos Observatorios Virtuales Teóricos.
Conclusiones
El desarrollo de la Astronomía esta íntimamente ligada a los avances tecnológicos, en el caso de los Observatorios Virtuales, las nuevas tecnologías de la información han facilitado a la comunidad científica el manejo de los enormes volúmenes de datos, generados por telescopios y como resultado de diferentes simulaciones numéricas, proporcionándoles una excelente herramienta para hacer investigación de frontera y ofreciendo la posibilidad de combinar la observación con la teoría y viceversa, con el objeto de entender el desarrollo de nuestro Universo.
Agradecimientos
Este trabajo fue parcialmente financiado por el proyecto PAPIIT IN121609-3 de la DGAPA, UNAM.
Bibliografía
Brunner, R., Djorgovski, S.G., Prince, T., & Szalay, A. 2002, in: Handbook of Massive Data Sets, eds. J. Abello et al., Dordrecht: Kluwer Academic Publ., p. 931.
Chandra X-Ray Observatory, https://physics.nist.gov/PhysRefData/Chandra/index.html
Djorgovski, S.G., & Beichman, C. 1998, BAAS, 30, 912.
Djorgovski, S. G.; Williams, R., 2005, From Clark Lake to the Long Wavelength Array: Bill Erickson’s Radio Science ASP Conference Series, Vol. 345, edited by N. Kassim, M. Perez, M. Junor, and P. Henning, p.517-530
Faint Images of Radio Sky at Twenty Centimeters, https://sundog.stsci.edu/
Hernández-Cervantes, L., González-Ponce A., Santillán A. and Salas G., “Computational backbone of the Mexican Virtual Solar Observatory”, VII Conferencia Latinoamericana de Geofísica Espacial, Mérida, Mérida, Yucatán, 2008.
Hubble Space Telescope, https://www.stsci.edu/hst/
International Virtual Observatory Alliance, https://www.ivoa.net/
Large Synoptic Survey Telescope, https://www.lsst.org/lsst
Mark Allen, Overview of VO applications, “Astronomy with Virtual Observatories”, Pune, India, Oct 15, 2007
Moore, G., 1965, “Cramming More Components onto Integrated Circuits”, Electronics Magazine Vol. 38, No. 8.
Observatorio Virtual Solar Mexicano, https://mvso.astroscu.unam.mx
Sloan Digital Sky Survay, https://www.sdss.org/dr3/index.html
TOPCAT, https://www.star.bris.ac.uk/
Two Micron All Sky Survey, https://www.ipac.caltech.edu/2mass/
Fuente: OEI/Revista Digital Universitaria [en línea] de la UNAM. Artículo original: “Observatorios Virtuales Astrofísicos “ Liliana Hernández Cervantes, Alfredo Santillán González y Alejandro R. González-Ponce. Revista de la UNAM, 10 de Octubre de 2009, Vol. 10, No. 10.
Material relacionado:
-
Big Universe, Big Data: Machine Learning and Image Analysis for Astronomy. Jan Kremer et al., Department of Computer Science, University of Copenhagen, April 18, 2017.
-
Data Mining: Is More Better?, Dan Gifford | Astrobites, Feb. 25, 2011.
-
Machine Learning in Astronomy, Ben Cook, Astrobites, Apr. 15, 2015 .
-
Teaching Computers How Galaxies Form, Benny Tsang, Astrobites, Mar 23, 2016 .
-
Smarter Computers Do More Work, Only Much Slower, Ben Cook, Astrobites, Jul 15, 2016.
La tremenda generación de datos de los nuevos proyectos de sondeo del cielo y otros, han motivado la necesidad no sólo de una mayor capacidad de almacenamiento, sino también mayor capacidad de procesamiento y posterior análisis para extraer nueva información, que deben realizarse al mismo ritmo de la adquisición de datos, de modo de poder ir encontrando nuevos objetivos de búsqueda para los instrumentos de registro (reorientando la búsqueda) y las investigaciones asociadas. Por supuesto , este tipo de tareas que deben realizarse al mismo ritmo de la adquisición de datos no son ejecutables por humanos, asi que debe recurrirse a procesos computacionales automáticos La especialidad que se dedica a dar respuestas a estos temas se denomina”Big Data” (Grandes Volúmenes de Datos) y también se aplica en una variedad de campos del conocimiento aparte de la Astronomía. Dentro de Big Data, el proceso cuyo objetivo es extraer nueva información a partir del conjunto de datos se denomina “Minería de Datos” ( su abreviatura en Inglés es “DM”, “Data Mining”).
A su vez “BIg Data” comparte y utiliza las herramientas de un tema mayor: La Inteligencia Artificial (su abreviatura en Inglés es”AI”, Artificial Intelligence).
Presentamos a continuación una serie de artículos sobre estos temas y ejemplos de su aplicación a los más diversos campos:
-
The AI Revolution in Science. Tim AppenzellerScience Magazine. Jul. 7, 2017. Contiene links a otros excelentes artículos.
-
Why Deep Learning is suddenly changing your life? Roger Parloff. Fortune Magazine, Sept 28, 2016.
-
Aprendizaje profundo. Robert D. Hof, traducido por Francisco Reyes. MIT Technology Review, 29 Abril, 2013.
-
The Dark Secret at the Heart of AI. No one really knows how the most advanced algorithms do what they do. That could be a problem. by Will Knight, MIT Technology Review. April 11, 2017.
-
Will AI Revolutionize Space Exploration?,
-
Artificial intelligence can turn 2D photos into real-world objects. Matthew Hutson, Science Magazine.
-
Deep Learning Creates Earth-like Terrain by Studying NASA Satellite Images. Emerging Technology from the arXiv, July 20, 2017. (Ver el artículo en Español, aquí.)
-
Casi humanos: así son los primeros razonamientos de la inteligencia artificial. Will Knight, traducido por Teresa Woods. 15 Mayo, 2017.
-
Computers are starting to reason like humans. Matthew Hutson. Science Magazine.
-
Football and Artificial Intelligence. Bob Hirshon, AAAs ScienceNetLinks, Science Update podcast. 2017.
-
Computer Composer. Bob Hirshon, AAAs ScienceNetLinks, Science Update podcast. 2017.
-
Harnessing Data for 21st Century Science and Engineering. National Science Foundation (NSF) Ideas for Future Investment. May 2016.
-
No es el robot físico el que va a quitar el trabajo”. Entrevista al Director del Instituto de Investigación en Inteligencia Artificial del CSIC, Ramón López de Mántaras. Crédito: MIT Technology Review. 21 de Julio, 2017.
Colecciones de artículos sobre “Inteligencia Artificial” en los medios:
-
Scientific American. También disponible en la biblioteca Timbó.
-
Nature. También disponible en Timbó.
-
Science AAAs.
-
IEEEXplore. También disponible en Timbó.
-
MIT Technology Review.
Sobre “Big Data” & “Data Mining”:
-
Red Española de Minería de Datos y Aprendizaje. Además de proporcionar links a libros, artículos y conferencias, y Grupos de trabajo, hace en la Presentación una descripción del DM.
-
Data mining: torturando a los datos hasta que confiesen, Luis Carlos Molina Félix, UOC.
-
What is Big Data, IBM.
-
-
The Discipline of Machine Learning. Tom M. Mitchell. School of Computer Science, Carnegie Mellon University. July, 2006.
-
Mining Our Reality, Tom M. Mitchell. School of Computer Science, Carnegie Mellon University. July, 2006.
-
Data-Mining 100 Million Instagram Photos Reveals Global Clothing Patterns. Emerging Technology from the arXiv, June 15, 2017.
-
Want to analyze millions of scientific papers all at once? Here’s the best way to do it. Lindsay McKenzie, Science Magazine.
-
Big biological impacts from big data. Mike May. Science Magazine.
-
Application and Exploration of Big Data Mining in Clinical Medicine. Yue Zhang,1 Shu-Li Guo,2 Li-Na Han,1 and Tie-Ling Li. Chinese Medical journal. Chin Med J (Engl). 2016 Mar 20; 129(6): 731–738. doi: 10.4103/0366-6999.178019.
-
How big data can improve manufacturing. Eric Auschitzky, Markus Hammer, and Agesan Rajagopaul. Mc Kinsey & Company.
-
Can ‘predictive policing’ prevent crime before it happens?. Mara Hvistendahl, Science Magazine.
-
CRISP-DM: Towards a Standard Process Model for Data Mining. Rüdiger Wirth, Jochen Hipp.
-
Could Big Data be the end of theory in science?. Fulvio Mazzocchi, Consiglio Nazionale delle Ricerche, Istituto dei Sistemi Complessi. EMBO Reports
Colecciones de artículos sobre “Big Data” en los medios:
-
Scientific American. También disponible en la bilioteca Timbó.
-
Nature. También disponible en Timbó.
-
Science AAAs.
-
IEEEXplore. También disponible en Timbó.
-
MIT Technology Review.
Videos:
Sobre Big Data y Data Mining:
-
Algoritmos , Marcus du Sautoy. BBC. June, 2016. Con la excelente categoría de producción de la BBC, Marcus du Sautoy explica con maestría qué son los algoritmos.
-
Big data y la minería de datos. Álex Rabasa. Ecommaster. En los primeros minutos del video Introduce los conceptos de Big Data y Data Mining. May 17, 2016.
-
Webinar “Big Data para Dummies”. Emilio Arias Leal. Spain Business School. 8 de Octubre, 2015.
-
Qué es Big Data. Juan David Vargas. mejorando.la. 6 de Mayo del 2013.
-
Big Data, Small World. Kirk Borne at TEDxGeorgeMasonU. June, 2013.
-
Big Data is Better Data. Kenneth Cukier. TED Talks. Con transcripción en Español.
-
The Beauty of Data Visualization. David McCandless. TEDGlobal 2010. July 2010. Con transcripción en Español
-
La Organización del Caos. Big Data y Astronomía. Jorge Ibsen | TEDxUDP. Agosto, 2015.
-
Solving astrophysics mysteries with big data | Melanie Johnston-Hollitt | TEDxChristchurch. Dec. 12, 2016.
-
Data. A collection of TED Talks (and more) on the topic of data.
Conferencias sobre Big Data:
-
Big Data Challenges and Opportunities. Prof. Sam Madden – Director, MIT Big Data Initiative. MIT Center for Transportation & Logistics.
-
The Future of Big Data. MIT Prof. Sam Madden. Prof. Sam Madden. IT Insider
-
Big Data debate. Alex Pentland and Andrew Keen .VodafoneInstitute. Nov. 2015.
Deep Learning: Intelligence from Big Data. VLAB, MIT Enterprise Forum Bay Area. Oct. 2014.
Sobre Inteligencia Artificial:
-
Inteligencia artificial – Documental.
-
Cómo Se Hizo. Inteligencia Artificial. Documental Subtitulado En Español.
-
Una pequeña historia de la inteligencia artificial, parte I. Víctor Amigó, U. P. Carmen de Michelena Tres Cantos. 13 ene. 2017.
-
Inteligencia artificial: el reto evolutivo de la humanidad | Miguel Sánchez | TEDxAlmendraMedieval.
-
Artificial intelligence. Ruud Mattheij at TEDxTilburg University. March, 2014.
-
The Age of Artificial Intelligence. George John at TEDxLondonBusinessSchool 2013.
-
A Friendly Introduction to Machine Learning. Luis Serrano, UDACITY. Sept. 2016.
-
A friendly introduction to Deep Learning and Neural Networks. Luis Serrano, UDACITY. Dec. 2016.
-
How we teach computers to understand pictures | Fei Fei Li. TED. Talks. March 2015.
-
How To Create A Mind: Ray Kurzweil at TEDxSiliconAlley. March 2013.
-
Emergence of Creativity in Artificial Intelligence. – Peter Bock – TEDxGWU. Nov. 17, 2011.
-
The long-term future of AI (and what we can do about it). Daniel Dewey at TEDxVienna. Dic. 2013.
-
¿La inteligencia artificial te dejará sin trabajo? | Federico Pascual is the Business Development Manager of Tyolabs | TEDxDurazno. Agosto, 2014.
-
AI. A collection of TED Talks (and more) on the topic of Articial Inteligence.
Conferencias sobre Inteligencia Artificial:
-
The Best Comprehensive Introduction of Artificial Intelligence (AI) and Machine Learning (ML). Dr. Joseph Reger. April, 2017.
-
The future and capabilities of artificial intelligence. Public Lecture with Google DeepMind’s Demis Hassabis. Nov., 2015.
-
The State of Artificial Intelligence. Davos 2016 – World Economic Forum. Matthew Grob, –Andrew Moore, –Stuart Russell, –Ya-Qin Zhang. January, 2016.
-
Deep Learning: Intelligence from Big Data. VLAB, MIT Enterprise Forum Bay Area. Oct. 2014.